This week we look at two technologies that are replacing the human factor – Google’s driverless cars and MIT’s image recognition algorithms. Both of these technologies are poised to shake up their respective industries, albeit in vastly different ways.
Google Creating a Driverless Car Company in 2016

Alphabet (now the parent company of Google), is planning to make its self-driving cars unit a stand-alone business next year. The idea is that the driverless cars will be a taxi or Uber replacement, offering rides for hire. This fits solidly with how Google has been talking about its driverless cars and where all that testing has gone. With tens of thousands of hours and only a few minor accidents (That were all caused by other drivers), Google seems extremely confident in the future of driverless cars.
What does this mean for Taxi companies and drivers? Well in Toronto drivers certainly weren’t happy with Uber, so who knows what the reaction will be worldwide in 5-10 years once this becomes the norm. We know that Uber itself opened up a self-driving car lab in 2015_ and its CEO has made no secret of the fact that they will be moving towards a driverless model in the future (even going so far as to say they ‘need self-driving cars to avoid ending up like the taxi industry’).
However, only days after this announcement, new rules from California regulators_ would severely restrict that idea. In fact, the proposal that requires ‘all driverless cars to have a steering wheel and pedals and a human driver’ kind of makes the whole thing pointless. Google’s whole point is that self-driving cars are much safer than human drivers, and it also ruins one of their main goals – that of accessible driving for people who can’t drive. Like blind people, those with disabilities, elderly and young children.
Google is so sure about this approach that their car designs don’t even include pedals or wheels. Google has already said these regulations would result in them testing their driverless cars in other states.
Making images more memorable
 Fitting neatly in the ‘creepy but also cool’ category, MIT’s Computer Science and Artificial Intelligence Laboratory developed an algorithm that predicts just how forgettable (or memorable) an image is almost as accurately as humans do.
Fitting neatly in the ‘creepy but also cool’ category, MIT’s Computer Science and Artificial Intelligence Laboratory developed an algorithm that predicts just how forgettable (or memorable) an image is almost as accurately as humans do.
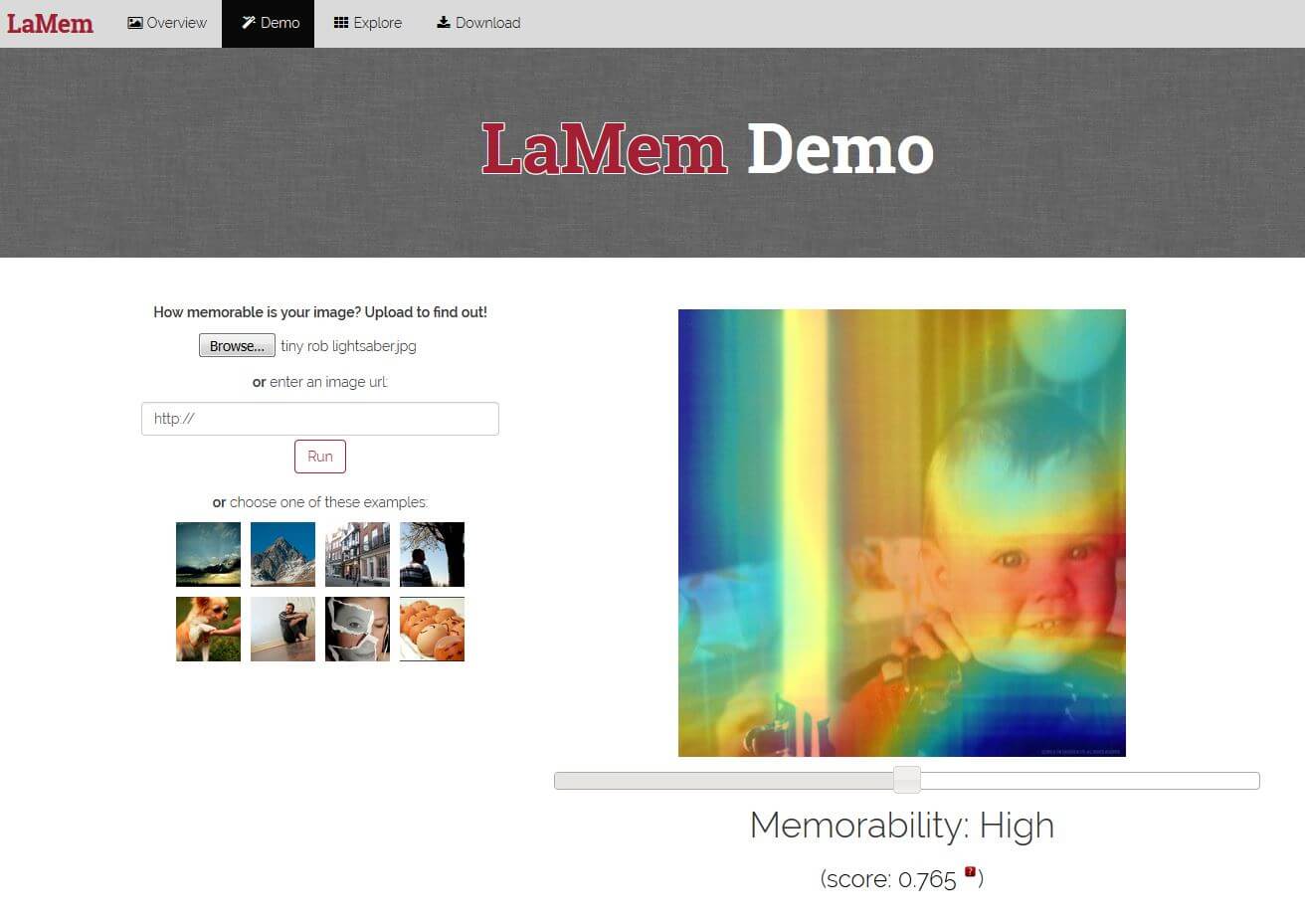
The output of this project is an app that will subtly tweak photos to make them more memorable. This actually has very interesting applications for branding and marketing in general, and ad creation for digital channels specifically. What if you could run all your ads through software that would statistically raise the likelihood of someone remembering it? The ‘MemNet’ algorithm (which sounds very terminator/skynet-ey to me) creates a heat map that identifies exactly which parts of the image are most memorable.
The technology using ‘deep-learning’ techniques to teach computers how to go through insane amounts of data to find patterns without outside help (much like the algorithms that drive Apple’s Siri, Google’s auto-complete and Facebook’s photo-tagging). The team put tens of thousands of images from different datasets together and gave each one a ‘memorability score’, then pitted its algorithm against human subjects. It performed 30% better than existing algorithms and was within a few percentage points of people.
You can test it out by uploading your own pictures here. I added a picture of me as a baby holding a lightsaber into their system and received a ‘highly memorable’ rating of 7.2. Because of course I did, it’s a baby with a lightsaber! (It’s a Star Wars thing, don’t worry about it too much).
Contact DAC today to find out more!



