Bonne nouvelle : vous avez décidé d’abandonner la mesure de l’attribution en dernier clic et vous avez pris la ferme résolution cette année d’améliorer votre analyse de l’attribution de la performance de vos canaux médias. La suppression des cookies tiers et votre capacité à mesurer la performance des canaux sont peut-être venus à bout de vos réserves ?
Ou bien, vous pensez simplement qu’il est temps de changer votre manière de mesurer vos campagnes médias de notoriété? Dans ce cas, la modélisation d’un mix média peut être une solution. Pourquoi ? Car cela permet de mesurer les performances sans les mêmes exigences que pour le suivi des parcours utilisateurs basés sur les impressions et les clics.
La modélisation du mix media n’est pas une méthode si récente
Il s’agit en effet d’une pratique vieille de 50 ans qui repose sur les deux principes suivants:
- Les ventes d’un produit sont déterminées par un ensemble de facteurs, comme notamment son prix, sa disponibilité, le nombre de concurrents, la taille du marché, ainsi que sa notoriété sur le marché et le désir des consommateur pour ce produit, le tout stimulés par la publicité et les offres promotionnelles.
- Lorsque les différents facteurs de ce mélange sont modifiés, les répercussions sur les ventes peuvent être mesurées. L’impact des différents facteurs peut alors être calculé à l’aide d’approches statistiques.
En bref, la modélisation du mix média vise à comprendre le poids relatif des différents canaux, ou des différentes étapes du parcours utilisateur sur les performances d’une campagne média.
La modélisation du mix média peut fournir un aperçu des conversions et des revenus de base et incrémentiels. En termes simples, les résultats incrémentiels sont le pourcentage de conversions touchées par les médias qui n’auraient pas eu lieu sans action marketing. L’analyse des résultats de base et incrémentiels peut révéler la notoriété et la fidélité d’une marque sur le long terme, ainsi que l’effet des activités publicitaires à court terme et des niveaux de concurrence.
Traditionnellement, les techniques statistiques établies, telles que la régression linéaire, ont été utilisées pour effectuer ces calculs, mais des outils plus sophistiqués apparaissent pour faire passer la modélisation du mix média au niveau supérieur.
Comment l’apprentissage automatique améliore la modélisation du mix média en 2023
Depuis les années 1960, les statisticiens ont patiemment effectué des analyses de modélisation du mix média à l’aide d’outils économétriques traditionnels tels que la régression linéaire, parfois même à la main. Mais les données médias sont devenues plus complexes au fil des années, et les lacunes des méthodes traditionnelles sont devenues de plus en plus évidentes. De même, les données médias sont devenues de plus en plus disponibles et granulaires, avec la multiplication des données de première partie enrichies par des données de deuxième et troisième partie. Enfin, la puissance de calcul des machines ayant été surmultipliée, toutes les conditions étaient réunies pour permettre l’application de nouvelles méthodes d’apprentissage automatique dans le cadre de l’analyse de la modélisation du mix média.
Certaines de ces approches, telles que Robyn— le progiciel open source de modélisation du mix marketing semi-automatisé et alimenté par le modèle ML de Meta, lancé en 2021 — cherchent à simplifier la technique, en permettant aux utilisateurs de “verser” leurs données de coût et de conversion dans un flux de traitement des données et de générer une sélection de modèles. En bref, l’apprentissage automatique simplifie le processus : il est capable d’ajuster de manière itérative et rapide le modèle pour obtenir de meilleures performances.
Alors il ne vous reste plus qu’à ajouter vos données et voilà ?
Vous pensiez vraiment que nous allions vous dire qu’une machine (ou pas si simple !) allait faire tout le travail ?
Même s’il est techniquement possible de simplement mettre les données dans la machine et de croiser les doigts pour que tout se passe bien, nous sommes convaincus de l’importance de la contribution stratégique des scientifiques de données, des statisticiens et des experts en marketing pour développer un modèle réellement pertinent et efficace.
Voici quelques situations où une enquête plus approfondie serait plus que bienvenue :
- Des ensembles de données différents peuvent être mieux adaptés à des analyses différentes utilisant des types de modèles différents
- Des ensembles de données différents peuvent bénéficier d’un “réglage” manuel de certains des paramètres requis par l’algorithme
- Les résultats du modèle peuvent tout simplement ne pas être exploitables : les recommandations du modèle ne sont peut-être pas alignées sur vos objectifs commerciaux ou les tactiques recommandées ne peuvent pas être déployées efficacement dans les canaux de marketing utilisés.
- Une première analyse préliminaire des données peut permettre de construire des modèles plus précis.
Explorons ce dernier cas un peu plus en profondeur. Par exemple, vous auriez pu décider d’inclure uniquement la recherche payante (paid search) dans votre analyse. Cela semble logique, mais au sein de chaque canal, il peut exister différents comportements des données, et ces schémas très différents peuvent limiter la précision du modèle :
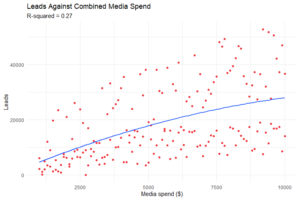
L’exploration des données avant la construction du modèle peut permettre de découvrir ces différences, par exemple entre les campagnes de mots-clés de marque et les campagnes de mots-clés génériques ou la variation des performances entre les régions, ce qui peut éclairer le processus de construction du modèle et améliorer sa précision :
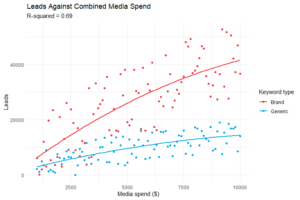
La myopie causée par les schémas cachés dans un ensemble de données concaténées peut conduire à des décisions discutables qui entraînent une prise de risque inutile et des conséquences potentiellement désastreuses sur la rentabilité de la campagne.
Ce qui peut arriver si vous faites aveuglément confiance à la machine et comment éviter les pièges
Parmi les effets négatifs potentiels d’une dépendance excessive en matière de tactiques de modélisation du mix média par apprentissage machine, vous pourriez par exemple finir par définir vos répartitions budgétaires de manière totalement inappropriée, en sur-investissant dans des canaux non pertinents ou en en sous-finançant d’autres. Vous pourriez également vous retrouver avec un modèle dont les résultats sont mal interprétés – ce serait le cas si l’on vous fournissait un modèle global pour l’ensemble de l’année alors que votre activité est en fait très saisonnière.
La solution ? Le bon sens, d’abord et avant tout. Se demander si ce que le modèle nous présente semble intuitivement logique, sur la base de sa connaissance du secteur, de l’entreprise, de ses produits, de ses succès passés.
Et la seconde option, complémentaire à la première : la mise en place d’un processus robuste de test et d’expérimentation, pour se donner la possibilité d’explorer tous les scénarios, même les plus inattendus, dans un environnement contrôlé.
Tous à bord du train de la modélisation du mix média ?
La version 2023 de la modélisation du mix média est-elle adaptée à chaque entreprise et à chaque secteur d’activité ? Elle l’est pour vous si :
- vous disposez de suffisamment de données et que vos données sont en bon état, car l’apprentissage automatique se nourrit d’une grande quantité de données propres;
- vous comprenez que les plateformes évoluent au fil du temps et que les données historiques ne sont pas toujours la meilleure représentation des performances futures d’une plateforme, et ce pour toutes les entreprises, y compris vos concurrents;
- ou vous recherchez des informations stratégiques de haut niveau sur l’impact et l’efficacité des canaux marketing. Si vous recherchez des informations plus granulaires et tactiques sur le rôle des différents points de contact à différentes étapes du parcours, vous ne devriez pas encore dire adieu à l’analyse des données de navigation (clickstream);
Nous espérons que cette première excursion dans le monde fascinant de la modélisation du mix média vous a aidé à vous poser les bonnes questions. N’hésitez pas à contacter nos experts pour déterminer si cette technique est la meilleure option pour votre entreprise.
CONTACTEZ-NOUS



