Les Grands Modèles Linguistiques, bien qu’encore aux balbutiements de leur potentiel développement, sont à bien des égards beaucoup plus intelligents que la moyenne des êtres humains. Non seulement ils en savent plus, mais ils ont une capacité beaucoup plus grande à traiter et à agir sur de vastes ensembles de données.
Nous avons récemment exploré leur potentiel pour interpréter ou générer du texte en tenant compte de nombreux paramètres. Nous avons démontré leur capacité extraordinaire à évaluer des blocs de texte non structurés et à les classer selon divers critères. De plus, nous avons pu générer un contenu spécifique et sur mesure en utilisant une série complexe d’instructions qui peuvent être ajustées avec une extrême précision.
Nous entrons dans une nouvelle ère de génération de contenu, alimenté par l’intelligence artificielle. En effet, les LLM produisent du contenu hyper ciblé, dont la pertinence et la segmentation sont extraordinairement efficaces. Ils placent à notre disposition un tableau de bord équipé de qui nous permet d’ajuster numériquement un même contenu marketing pour divers formats.
Ici, nous partageons les premières conclusions de nos expériences et offrons une méthodologie générale pour exploiter les LLM afin d’extraire des mesures quantitatives à partir de textes autrement non structurés, ouvrant la porte à l’analyse statistique et à l’optimisation de la création de contenu.
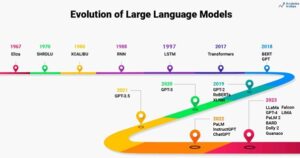
Source: Analytics Vidhya
Les grands modèles linguistiques sont parfaitement adaptés pour développer des idées
Les grands modèles linguistiques (LLM) sont construits à l’aide de vecteurs mathématiques. Cette base leur permet de traduire habilement des blocs de texte, notant, évaluant ou cartographiant le contenu en valeurs numériques qui capturent les qualités distinctes de chaque bloc. Par exemple, nous pouvons demander au modèle d’évaluer à quel point ce blog est “technique” sur une échelle de 1 à 10, avec des critères définis par l’utilisateur. Si le résultat n’est pas celui attendu, les LLM peuvent corriger le contenu et le mettre en adéquation avec les attributs soumis par l’utilisateur. Par exemple, vous pouvez demander aux LLM d’écrire un article de blog avec un degré de technicité noté 9 sur 10.
Nous pouvons inclure de multiples concepts pour construire un espace conceptuel complexe. C’est ce que nous appelons un Espace Cartésien Conceptuel, auquel les LLM peuvent se référer pour la génération de contenu. Nous pouvons placer un point dans cet espace pour définir une idée en fonction de sa position par rapport à chacun des axes qui définissent notre espace.
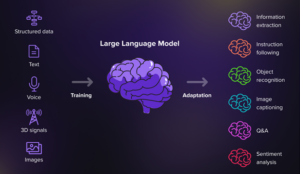
Source: https://serokell.io/blog/language-models-behind-chatgpt
Nos expériences et conclusions
Nous avons mené une série d’expériences pour valider l’efficacité et la flexibilité de la cartographie cartésienne conceptuelle à l’aide des LLM. Nous avons adopté une approche “bottom-up” pour valider notre méthodologie, en commençant par des expériences de base et en augmentant la complexité à chaque étape.
- Expérience sur les gradients
Cette expérience explore la capacité des LLM à échelonner le contenu le long de gradients linéaires, offrant aux utilisateurs un contrôle dans la génération ou l’évaluation d’un texte. Nous avons examiné différentes plages d’échelles (1-10, 1-100) et avons démontré l’adhérence du modèle à des cadres d’évaluation spécifiques. Les résultats confirment la capacité du modèle à suivre méthodiquement les gradients choisis.
- Expérience sur les méthodes de notation alternatives
Dans cette expérience, nous avons testé l’influence des méthodes de notation alternatives sur la génération de texte. Les LLM sont instruits d’appliquer divers cadres d’évaluation, illustrant l’adaptabilité du modèle. On lui demande du contenu sur des sujets spécifiques avec des règles strictes. Nous avons ainsi, par exemple, requis un critère psychologique pour noter (ou diagnostiquer) les scores d’empathie pour un bloc de contenu.
- Expérience dans l’espace multidimensionnel
Cette expérience explore la performance du modèle dans des espaces multidimensionnels. L’étude introduit des concepts tels que la praticité et la technicité en tant qu’axes supplémentaires, illustrant la capacité des LLM à manipuler des idées complexes et plusieurs dimensions de manière efficace. Les résultats indiquent l’agilité du modèle pour naviguer dans des espaces multidimensionnels complexes.
- Expérience dans un espace relatif non spécifié
Cette expérience explore la capacité des LLM à analyser quantitativement des idées par rapport à d’autres idées, sans gradients le long d’un seul axe. Une application pratique importante pour les spécialistes du marketing est de positionner le contenu par rapport aux concurrents ; nous avons demandé aux GML de générer une politique de logement pour un candidat fictif à la mairie positionné quantitativement par rapport à plusieurs candidats existants.
Notre étude a démontré la capacité du modèle à gérer des tâches de génération de contenu avec une précision quantitative, montrant son potentiel dans des environnements où les idées manquent de cadres prédéfinis stricts.
Attachement de mesures de performance standard
Si nous associons la position cartésienne conceptuelle du contenu à des mesures traditionnelles, nous pouvons analyser la performance du contenu publié par rapport aux données numériques nouvellement disponibles. Par exemple, nous pouvons étudier les publications sur les média sociaux (c’est-à-dire les likes, les partages, les taux de clics) par rapport aux scores conceptuels attribués par le modèle pour des attributs tels que l’humour, l’empathie et la technicité. Grâce à l’analyse statistique, nous pouvons identifier le mélange optimal de chaque attribut conceptuel pour un contexte donné et utiliser cette position de coordonnées pour générer un nouveau contenu avec une performance encore meilleure.
La combinaison innovante de la cartographie cartésienne conceptuelle et des grands modèles linguistiques nous offre une approche nouvelle, méthodique et précise de la création de contenu en général. Pour une performance toujours plus pointue.
Les entreprises peuvent cibler et adapter leur message avec précision, assurant un engagement maximal de leur public cible tout en positionnant leur contenu par rapport aux concurrents. Les campagnes politiques notamment peuvent s’enrichir de propos nuancés par rapport à d’autres candidats ou aux résultats des sondages. Les établissements éducatifs, autre exemple, peuvent créer des supports d’apprentissage personnalisés, améliorant l’intérêt et la compréhension des étudiants au niveau individuel.
Vous voulez être prêt pour ce futur ? Parlez à un stratège DAC dès aujourd’hui !
CONTACTEZ-NOUS



