¿Has decidido alejarte de un modelo de medición para la atribución asociado al último clic y mejorar el análisis de los resultados en las campañas de medios? Seguramente, una de las razones, sea la próxima eliminación de las cookies de terceros y como afectará esto a la campacidad para medir el rendimiento de los canales. O tal vez simplemente ha llegado el momento de cambiar la forma de medir los medios, en este caso, la modelización de la combinación del mix de medios puede ser la solución. ¿Por qué? Principalmente porque permite conocer el rendimiento sin los mismos requisitos que el seguimiento del usuario basado en impresiones y clics.
La modelización del mix de medios no es una novedad
Es una práctica de 50 años basada en los dos principios:
- Las ventas de un producto están determinadas por una serie de factores, como su precio, disponibilidad, la cantidad de competidores, tamaño del mercado, conocimiento del mercado y deseo de los consumidores por el producto, todos ellos estimulados por la publicidad y las ofertas o promociones.
- Cuando se modifican los diferentes factores que componen esta combinación, puede medirse el impacto en las ventas. El impacto de los distintos factores puede calcularse a partir de enfoques estadísticos.
En pocas palabras, la modelización del mix de medios pretende comprender el peso relativo de los distintos canales, o de las distintas etapas del recorrido del usuario, en el rendimiento de una campaña de medios.
La modelización del mix de medios puede aportar una idea de las conversiones y los ingresos de referencia e incrementales. En términos más simples, los resultados incrementales son el porcentaje de conversiones alcanzadas por los medios de comunicación que no se habrían producido sin la acción de marketing. El análisis de los resultados de referencia e incrementales puede revelar el conocimiento y la fidelidad a la marca a largo plazo, así como el efecto de las actividades publicitarias a corto plazo y los niveles de competencia.
Tradicionalmente, se han utilizado técnicas estadísticas establecidas, como el análisis de regresión lineal, para realizar estos cálculos, pero están surgiendo herramientas más sofisticadas para desarrollar modelos de atribución mucho más avanzados.
Cómo el machine-learning tiene la capacidad de mejorar la modelización del mix de
Desde los años sesenta, los estadísticos han realizado pacientemente análisis de modelización del mix de medios utilizando herramientas econométricas tradicionales, como la regresión lineal, a veces incluso a mano. Pero los datos sobre medios de comunicación se han vuelto más complejos con el paso de los años, y las deficiencias de los métodos tradicionales se han hecho cada vez más evidentes. Del mismo modo, los datos de los medios de comunicación son cada vez más accesibles y granulares, con la proliferación de first-party data enriquecidos con la second and thrid-party data. Por último, al haberse disparado la potencia de cálculo de machine-learning, se han dado las condiciones adecuadas para la aplicación de nuevos métodos de aprendizaje automático en el análisis de modelos de análisis para campañas de mix de medios.
Algunos de estos enfoques, como Robyn— El software open source semiautomatizado del modelado de marketing mix de código abierto, lanzada para Meta en 2021 — intenta simplificar la metodología, permitiendo a los usuarios “volcar” sus datos de costes y conversión en un flujo de procesamiento de datos y generar una selección de modelos. En resumen, el machine-learning simplifica el proceso: es capaz de ajustar iterativa y rápidamente el modelo para lograr un mejor rendimiento.
¿Sólo tienes que conectar los datos y ya está ?
¿De verdad pensabas que con un simple (¡o no tan simple!) aplicación del machine-learning sería suficiente?
Aunque es técnicamente posible, introducir los datos y confiar que el sistema de machine-learning haga todo el trabajo es un tanto arriesgado, más nos vale cruzar los dedos para que todo vaya bien. Por tanto, será esencial contar con la aportación de expertos en data science para desarrollar un modelo de atribución pertinente y eficaz.
He aquí algunas situaciones en las que una investigación en profundidad será necesaria:
- Diferentes conjuntos de datos pueden ser más adecuados para diferentes análisis utilizando diferentes tipos de modelos.
- Los distintos conjuntos de datos pueden beneficiarse del “ajuste” manual de algunos de los parámetros requeridos por el algoritmo
- Los resultados del modelo pueden simplemente no ser utilizables: las recomendaciones del modelo de atribución pueden no estar alineadas con los objetivos de negocio o incluso las tácticas recomendadas pueden no desplegarse eficazmente en los canales de marketing que se están utilizando..
- Un primer análisis preliminar de los datos puede servir para construir modelos más precisos.
Analicemos un poco más este último caso. Por ejemplo, puede que se haya decidido incluir la “búsqueda de pago” como un único canal en el análisis. Inicialmente puede parecer lógico, pero dentro de cada canal puede haber diferentes comportamientos de los datos, y estos comportamientos tan diferentes pueden limitar la precisión del modelo:
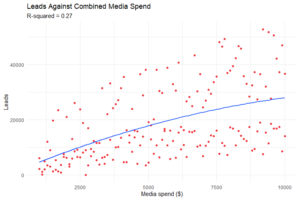
Explorar los datos antes de construir el modelo puede descubrir estas diferencias, por ejemplo, entre campañas de palabras clave de marca y genéricas o la variación de rendimiento entre regiones, lo que puede informar el proceso de construcción del modelo y mejorar su precisión.
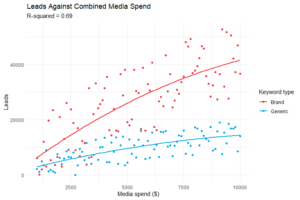
La miopía causada por patrones ocultos en un conjunto de datos concatenados puede llevar a decisiones cuestionables que desemboquen en una asunción de riesgos innecesaria, y por tanto siendo un desastre para la rentabilidad de la campaña.
Qué puede ocurrir si se confía ciegamente en el machine-learning y cómo evitar las trampas
Entre los posibles efectos negativos de confiar demasiado en las tácticas de modelización del mix de medios del machine-learning está el de acabar fijando las asignaciones presupuestarias de forma totalmente inadecuada, invirtiendo en exceso en canales irrelevantes o infrautilizando otros. Otra posibilidad es terminar utilizando un modelo de atribución cuyos resultados den lugar a malinterpretaciones, como ocurriría por ejemplo si nos basamos en un mismo modelo para todo un año mientras que la realidad de nuestro negocio es que su funcionamiento es estacional.
¿La solución? Ante todo, sentido común. Debemos preguntarnos si los datos que arrojan nuestro modelo están basadas en la intuición, en el conocimiento del sector, el tipo de empresa o negocio, los productos o tal vez los éxitos del pasado.
Y tenemos un segundo escenario, complementario del primero: la puesta en marcha de un sólido proceso de pruebas y experimentación, para dar la posibilidad de explorar todos los escenarios, incluso los más inesperados, en un entorno controlado.
¿Todos estamos a bordo del tren de la modelización del mix de medios?
¿Es la versión 2023 de los modelos de atribución sobre el mix de medios adecuada para todas las empresas y los sectores? Lo es :
- Tienes suficientes datos y los datos son los adecuados, porque el machine-learning se alimenta de una gran cantidad de “datos limpios”;
- Las plataformas evolucionan con el tiempo y basarnos en el histórico de datos no siempre es la mejor representación del rendimiento a futuro, incluido el comportamiento de los competidores;
- Llevar a cabo investigaciones para informarnos sobre sobre el impacto y la eficacia de los canales de marketing. No obstante, si fuera necesario disponer de una información más granular y táctica sobre el papel de los distintos puntos de contacto en las diferentes etapas del viaje el análisis de los datos de navegación (clickstream) debería ser un punto a tener en cuenta;
Esperamos que esta primera introducción en complejo, pero a la vez fascinante, mundo de los modelos de atribución para el mix de medios te ayude a plantearte las preguntas adecuadas. Este es el primer gran paso. No dudes en ponerte en contacto con nuestros expertos para averiguar cual es el mejor approach para tu negocio.
CONTÁCTANOS



